Designing incident response that doesn't break your team
The incident itself is rarely the problem. The technology almost always has a path to resolution. The hard part is the chaos that surrounds it.
Unclear ownership. Nobody knows who’s in charge. Five people have SSH’d into the same server. The product manager is asking for updates in one Slack channel, the CEO is asking in another, and your on-call engineer is trying to respond to both while also debugging.
That chaos is a design failure.
And it’s a design failure that was solved fifty years ago. By firefighters.
#The fires that changed everything
On September 26, 1970, a fire broke out near Laguna Beach, California. Within days, 773 separate fires were burning across Southern California simultaneously. By the time they were contained, 16 firefighters were dead, more than 700 structures had burned, and over 500,000 acres of land had been destroyed. The financial toll exceeded $230 million.
The investigation that followed found something disturbing. The fires hadn’t overwhelmed the firefighters because of the scale of the flames. They overwhelmed them because the agencies responding couldn’t work together.
Dozens of departments from different cities, counties, and federal jurisdictions showed up to fight the same fires. They brought incompatible radios. They used different terminology for the same commands — one agency’s “evacuation” meant something different to another’s. There was no unified command structure, so multiple incident commanders were issuing conflicting orders to the same personnel. Some areas had twenty firefighters responding to a single burning structure. Others had no one.
The firefighters weren’t failing. The system was failing them.
#FIRESCOPE and the invention of ICS
The following year, the U.S. Forest Service, the California Division of Forestry, and several southern California fire departments launched a joint initiative called FIRESCOPE — Firefighting Resources of California Organized for Potential Emergencies. Their mandate was to design a command system that would actually work at scale, across agency boundaries, in the chaos of a major incident.
What they built over the next several years became the Incident Command System.
The design principles were born from direct analysis of what had failed in 1970. Radio interoperability was a technical problem and could be solved with the right equipment. But the coordination failures were structural. They came from ambiguity: ambiguity about who was in charge, what terms meant, what role each person was supposed to play, and how decisions would be made and communicated.
ICS addressed this by standardizing the things that couldn’t be left to interpretation. One Incident Commander per incident. A fixed set of functional roles — Operations, Planning, Logistics, Finance/Administration — that meant the same thing regardless of which agency you came from. Common terminology enforced across all participants. A defined span of control: no commander oversees more than seven people, and three to five is optimal. And a structure designed to scale — small incidents use only what’s needed; large incidents expand the same hierarchy without adding new concepts.

The system was piloted in California through the mid-1970s, refined through real incidents, and formally adopted as a national standard in the 1980s. By the 1990s, it was the operating model for wildfire response across the American West.
Then September 11 happened.
#From wildfire to everywhere
The September 11 attacks and Hurricane Katrina in 2005 exposed coordination failures at a national scale. Multiple federal agencies with overlapping jurisdictions, local authorities and federal responders operating under different command structures, communication breakdowns that were eerily similar to what FIRESCOPE had studied after 1970.
The Department of Homeland Security’s response was to mandate ICS universally. In 2004, FEMA established the National Incident Management System — and ICS became its operational backbone. Every emergency responder in the United States, from a rural volunteer fire department to the National Guard, is now required to be ICS-certified. The same principles that came out of the 1970 California fires now govern hurricane response, mass casualty events, chemical spills, and search and rescue operations across the country.
ICS also crossed into adjacent domains. Hospitals use a derivative called HICS — the Hospital Incident Command System — to manage mass casualty events and internal disasters. Utilities use it for grid restoration after major outages. FEMA’s Community Emergency Response Teams train civilians in ICS basics. The Red Cross runs on it.
A framework developed to prevent firefighters from dying in California wildfires became the operating model for emergency response in America.
#The quiet adoption in tech
Here’s where it gets interesting, and where most of the engineering world has no idea what they’re using.
Google’s Site Reliability Engineering book, published in 2016, included a chapter on managing incidents. It described an “Incident Command” role — a single coordinator who manages communication and delegates technical work, explicitly modeled on ICS. The book credited the origin. But the term traveled much further than the footnote.
Atlassian, PagerDuty, AWS, and dozens of other companies published incident response frameworks in the years that followed. “Incident Commander.” “Comms Lead.” “Operations Lead.” “Scribe.” These titles are now standard vocabulary in engineering organizations around the world. The concepts behind them — unified command, defined roles, explicit handoffs, span of control — are ICS, adapted for a Slack-and-PagerDuty environment.
Most of the engineers using these roles have no idea they’re running a protocol designed for wildfire suppression. The Incident Commander title on your on-call rotation sheet traces a direct line back to firefighters in Laguna Beach in 1970.
I find that worth knowing. Not for trivia. But because understanding why ICS was designed the way it was makes its principles a lot easier to follow, and a lot harder to dismiss.
The people who built ICS were responding to a body count. The constraints they encoded weren’t bureaucratic preferences. They were lessons extracted from failure and death, refined through decades of high-stakes operational use. The reason “one Incident Commander” is a hard rule and not a guideline is because organizations that treated it as a guideline had people die for it.
In tech, the stakes are lower. But the failure modes are the same, and the solutions still work.
#In high school, I learned this without knowing it
I was part of the San Jose Fire Explorer Program, a program run through the fire department where we trained in structure search, hose work, and ladder operations with real drills at a real burn building.

We trained under ICS without me fully understanding what ICS was. There was always a clear IC. Roles were named and assigned before the drill started. Communication went through defined channels. Handoffs followed a format.
When I started managing production incidents years later, ICS wasn’t a foreign framework I had to learn. It was the obvious answer to a problem I’d already seen solved. The chaos I kept seeing in engineering organizations — the five people on the same SSH session, the parallel Slack threads, the undefined ownership — looked exactly like the coordination failures FIRESCOPE had analyzed in 1971.
The technology has changed. The failure mode hasn’t.
#The four things that actually matter
If you take nothing else from this:
One Incident Commander. There is always exactly one person with decision-making authority. Not a committee. Not whoever speaks up first. One person, named and accountable.
Clear roles — so people know what they’re supposed to do and, crucially, what they’re not supposed to do. Scope creep in an incident is as dangerous as scope creep in a project.
Defined communication channels — one place for incident updates, one place for stakeholder communication. Not twelve parallel threads.
Explicit handoffs — so that when someone steps out, the knowledge they’re carrying doesn’t walk out with them.
#The IC’s job is to direct, not do
This is the hardest thing to internalize for engineers who are used to being the strongest technical person in the room. The instinct when something is broken is to fix it — get your hands on the keyboard, pull up the logs, start solving.
But when you are the IC, that instinct is wrong.
The moment you go heads-down on a technical problem, you’ve stopped being the IC. You’ve created a command vacuum. And the incident will fill that vacuum with chaos.
The IC’s job is to maintain the view from 30,000 feet. Assign who does what. Make decisions when the team is stuck. Manage communication. Set priorities. That’s it.
The doing is someone else’s job.
#The command structure scales with the incident
For small incidents, the IC handles everything. But as incidents scale — more responders, more stakeholders, longer duration — the IC delegates:
- Communications Lead: owns all messaging. Internal updates, status page, customer-facing communication. They draft, the IC approves.
- Operations Lead: hands-on technical mitigation. Your strongest technical responder goes here, executing on the plan.
- Planning Lead: tracks the timeline, documents decisions and next steps, is thinking two moves ahead. If the Ops Lead is in the present tense, the Planning Lead is in the future tense.
- Logistics Lead: makes sure everyone has what they need — access, tooling, staffing. If someone needs a database credential reset at 3am and can’t reach anyone, that’s a logistics failure.
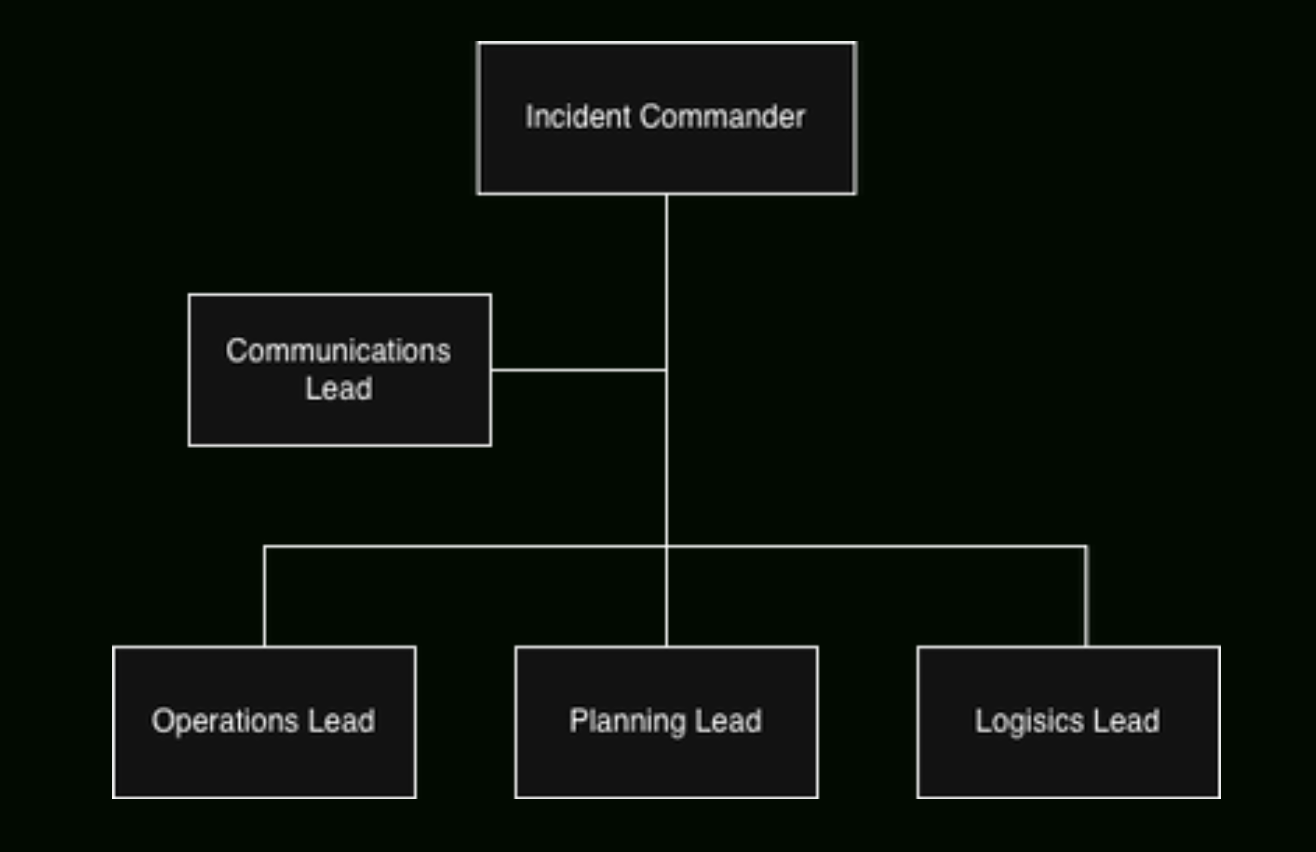
This maps directly to the ICS functional sections: Operations, Planning, Logistics, Finance/Administration. The tech version drops Finance (usually) and collapses some functions, but the structure is identical. Firefighters have been running this model for fifty years.
#Severity is based on customer impact. Not technical complexity
A control plane in a degraded state with no customer-facing impact is not a SEV1. A login page returning errors for 10% of users is a SEV1, even if the root cause is a two-line config change.
Severity is always about customer and business impact. And it can change as you learn more — you start where you are and you adjust. The specific thresholds matter less than having them defined before an incident starts. The worst time to debate severity is during an active incident.
#Sustainable on-call is a reliability problem
We’ve all heard “we should take care of our engineers.” While true, it doesn’t always move the needle in planning conversations. So let’s put it differently:
A fatigued engineer makes worse decisions. They miss things. They communicate poorly. They stay heads-down when they should be coordinating. They don’t hand off when they should. When they burn out entirely, you lose institutional knowledge that’s almost impossible to replace.
Responder health is not a people problem. It’s a reliability problem.
No one should serve as Incident Commander for more than two hours without a rotation plan. Two hours of sustained, high-stakes coordination is cognitively exhausting. For any incident running longer than two hours, the IC should be planning their handoff before the two-hour mark — not when they’re already burnt out.
ICS has known this since the 1970s. Incident Command for extended operations explicitly includes mandatory rest cycles and shift rotation. The engineers who built your on-call rotation didn’t invent that idea. They inherited it from people who learned it fighting wildfire.
#The handoff is the reliability practice
Most teams treat the role handoff as an interruption to the real work — something to get through quickly so the next person can start fixing things. That’s wrong.
A well-executed handoff keeps institutional knowledge in the incident as individuals cycle out. A bad handoff — or no handoff — is how critical context gets lost and incident duration doubles.
Every handoff must include:
- Current status and severity
- What’s been tried and what worked or didn’t
- Active mitigation steps
- Known risks and open questions
- Outstanding action items
Document it. Announce it to the incident channel. Not passed privately in a DM.
#Treat every incident like an incident
The ICS structure only works if you use it every single time. SEV2 bug? Declare an IC, log it. SEV3? Same thing.
The process should feel boring on the small ones — because boring means it’s muscle memory. And when the SEV1 hits at 2am, nobody is reading a runbook. They’re already in position.
Tabletop exercises help. Fire drills help. But nothing builds the reflex like actual reps. The teams that handle major incidents well aren’t calmer under pressure — they’ve done the process so many times on small incidents that the roles activate automatically.
This is also how ICS was designed to be trained. You practice on the small fires so the big ones don’t require improvisation.
#Blameless postmortems, or you’re wasting the incident
Every incident that reaches SEV2 or higher should have a postmortem. No exceptions.
And it must be genuinely blameless — not “we won’t fire anyone over this,” but analysis focused on system failures and process gaps, not individual performance. The moment people think they’ll be blamed, they stop being honest. And you lose the ability to learn.
A good postmortem produces specific, actionable follow-up items. Not “we should improve monitoring” — but “we need an alert on X metric with a threshold of Y by this date, owned by this person.”
The cost of the incident has already been paid. The downtime happened. The engineers were paged. The customers were affected. That cost is sunk.
The postmortem is how you get the return on that cost. Organizations that take it seriously reduce incident frequency, reduce mean time to resolution, and get more resilient. The organizations that skip it just pay the same cost again next quarter.
An incident without a postmortem is a lesson you’ll have to learn again.
The next time you’re running an incident and you assign an Incident Commander, write up the timeline, or hand off to the next shift — you’re using a system that was built to stop firefighters from dying. It worked. It’s been tested against conditions that make a database outage look trivial.
Use it like you mean it.